Chapter 9: 미국 Foundation Model 연구소 — PI, Generalist, Skild, Figure
개요
PI, Generalist, Skild, Figure는 모두 generalist를 말하지만 데이터 출처, embodiment, action interface, 접촉 채널, production evidence가 다르다. 이 장은 그 문제를 제조 셀의 데이터 계약으로 다시 쓴다. [1]와 [2]가 보여주는 대규모 로봇 데이터의 약속은 중요하지만, 제조에서는 episode가 품질 판정과 연결될 때만 가치가 생긴다.
PI는 pi0/OpenPI로 연구 공개성이 높고, Figure는 humanoid hardware와 회사 발표가 강하며, Generalist와 Skild는 현재 공개 기술 세부가 제한적이다. 따라서 같은 표 안에서도 evidence tier를 분리해야 한다. 이때 데이터는 카메라 프레임만이 아니라 손의 선택, force/torque, tactile patch, controller mode, 작업자 개입, 검사 결과를 함께 담는다. [3]와 [4]는 사람 데이터가 로봇 실행으로 넘어갈 때 어떤 신호가 사라지는지 보여준다.
이 장을 읽고 나면... - 제조 조작 문제를 모델 성능이 아니라 데이터 계약으로 설명할 수 있다. - 2지/흡착/custom/5지 손의 선택이 수집 비용과 실패 관측성을 어떻게 바꾸는지 말할 수 있다. - 논문, 회사 발표, 생산 현장 claim을 evidence tier로 분리할 수 있다. - 첫 제조 PoC에서 반드시 기록할 replay set과 QA trace를 설계할 수 있다.
핵심 지도
그림으로 보는 장의 논지

그림 9.1. Company landscape for large-data manipulation. 출처: 로컬 서베이 자산 재사용 또는 저자 작성.
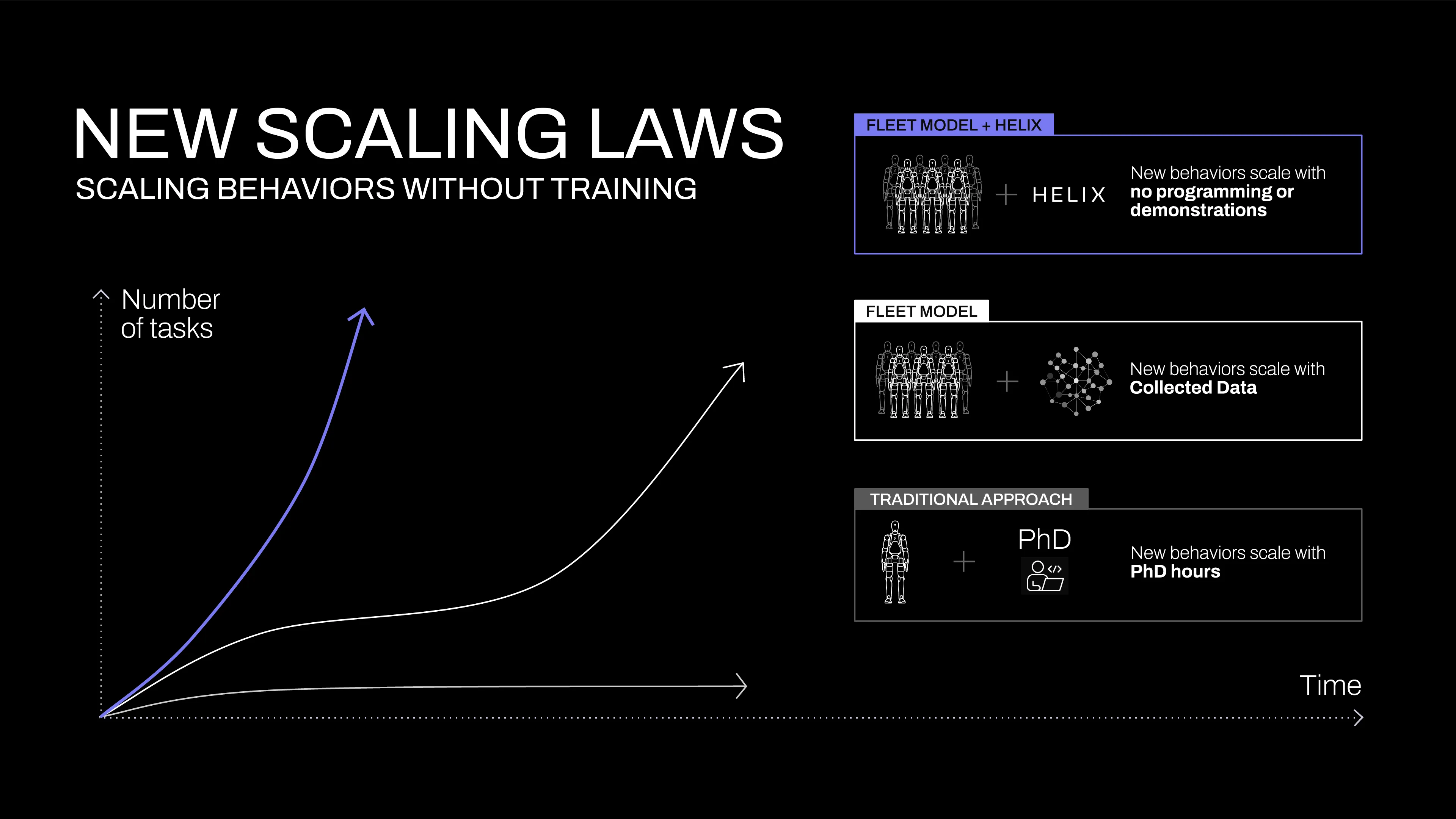
그림 9.2. Figure Helix as company-reported humanoid VLA stack. 출처: 로컬 서베이 자산 재사용 또는 저자 작성.
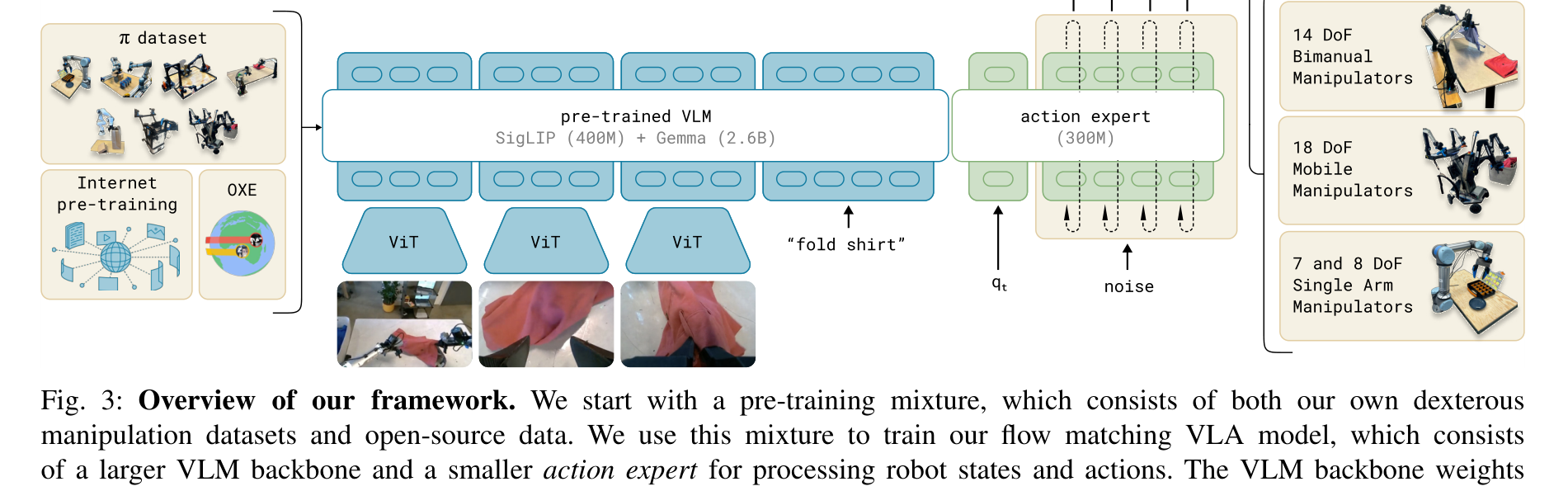
그림 9.3. pi0 family as a generalist policy reference point. 출처: 로컬 서베이 자산 재사용 또는 저자 작성.
generalist라는 단어를 분해하기
generalist라는 단어를 분해하기의 핵심은 공정 변수를 학습 가능한 형태로 남기는 것이다. [1]는 대규모 데이터가 embodiment와 task family를 넓힐 수 있음을 보여주지만, 제조 셀은 그보다 좁고 엄격하다. 같은 물체를 집어도 fixture tolerance, 표면 오염, cycle time 압박, 검사기의 reject code가 달라지면 사실상 다른 데이터 분포가 된다.
여기서 PI는 pi0/OpenPI로 연구 공개성이 높고, Figure는 humanoid hardware와 회사 발표가 강하며, Generalist와 Skild는 현재 공개 기술 세부가 제한적이다. 따라서 같은 표 안에서도 evidence tier를 분리해야 한다.라는 구체 시나리오를 보면, 사람의 시연만으로는 충분하지 않다. [2]처럼 사람-로봇 전환을 쉽게 만드는 인터페이스가 있어도, 접촉 힘과 실패 이유가 빠지면 policy는 다음 release에서 같은 실수를 반복한다. 따라서 episode schema는 observation, action, contact state, QA outcome, operator note를 같은 key로 묶어야 한다.
증거 수준도 분리해야 한다. [3] 같은 논문은 재현 가능한 benchmark와 방법론을 제공하는 반면, 회사 발표는 실제 배포 방향을 알려주지만 데이터 권리와 운영 metric은 제한적으로 공개한다. 제조사는 둘을 같은 표에 넣되 같은 무게로 읽으면 안 된다. peer-reviewed 또는 arXiv 근거, 공식 기술 페이지, press/media claim, 미검증 watchlist를 나누어야 한다.
제어 관점에서는 learned policy가 모든 것을 결정하지 않는다. force limit, guarded motion, fixture state, collision zone, rollback condition이 policy 앞뒤에 있어야 한다. 이 경계가 없으면 large-data 전략은 더 많은 데이터를 모아도 현장에서 더 많은 안전 stop과 rework를 만들 수 있다.
운영 관점에서는 성공률보다 실패의 재현성이 중요하다. 실패가 replay set으로 들어가고, 다음 model update가 그 replay set을 통과하고, 배포 후 같은 failure code가 줄어드는지 확인되어야 flywheel이 닫힌다. 이 장의 질문은 그래서 'generalist라는 단어를 분해하기을 어떻게 설명할까'가 아니라, 어떤 로그가 없으면 이 주장이 현장에서 무너지는가이다.
PI와 OpenPI의 공개성
PI와 OpenPI의 공개성의 핵심은 공정 변수를 학습 가능한 형태로 남기는 것이다. [4]는 대규모 데이터가 embodiment와 task family를 넓힐 수 있음을 보여주지만, 제조 셀은 그보다 좁고 엄격하다. 같은 물체를 집어도 fixture tolerance, 표면 오염, cycle time 압박, 검사기의 reject code가 달라지면 사실상 다른 데이터 분포가 된다.
여기서 PI는 pi0/OpenPI로 연구 공개성이 높고, Figure는 humanoid hardware와 회사 발표가 강하며, Generalist와 Skild는 현재 공개 기술 세부가 제한적이다. 따라서 같은 표 안에서도 evidence tier를 분리해야 한다.라는 구체 시나리오를 보면, 사람의 시연만으로는 충분하지 않다. [5]처럼 사람-로봇 전환을 쉽게 만드는 인터페이스가 있어도, 접촉 힘과 실패 이유가 빠지면 policy는 다음 release에서 같은 실수를 반복한다. 따라서 episode schema는 observation, action, contact state, QA outcome, operator note를 같은 key로 묶어야 한다.
증거 수준도 분리해야 한다. [6] 같은 논문은 재현 가능한 benchmark와 방법론을 제공하는 반면, 회사 발표는 실제 배포 방향을 알려주지만 데이터 권리와 운영 metric은 제한적으로 공개한다. 제조사는 둘을 같은 표에 넣되 같은 무게로 읽으면 안 된다. peer-reviewed 또는 arXiv 근거, 공식 기술 페이지, press/media claim, 미검증 watchlist를 나누어야 한다.
제어 관점에서는 learned policy가 모든 것을 결정하지 않는다. force limit, guarded motion, fixture state, collision zone, rollback condition이 policy 앞뒤에 있어야 한다. 이 경계가 없으면 large-data 전략은 더 많은 데이터를 모아도 현장에서 더 많은 안전 stop과 rework를 만들 수 있다.
운영 관점에서는 성공률보다 실패의 재현성이 중요하다. 실패가 replay set으로 들어가고, 다음 model update가 그 replay set을 통과하고, 배포 후 같은 failure code가 줄어드는지 확인되어야 flywheel이 닫힌다. 이 장의 질문은 그래서 'PI와 OpenPI의 공개성을 어떻게 설명할까'가 아니라, 어떤 로그가 없으면 이 주장이 현장에서 무너지는가이다.
Figure의 humanoid-stack 전략
Figure의 humanoid-stack 전략의 핵심은 공정 변수를 학습 가능한 형태로 남기는 것이다. [7]는 대규모 데이터가 embodiment와 task family를 넓힐 수 있음을 보여주지만, 제조 셀은 그보다 좁고 엄격하다. 같은 물체를 집어도 fixture tolerance, 표면 오염, cycle time 압박, 검사기의 reject code가 달라지면 사실상 다른 데이터 분포가 된다.
여기서 PI는 pi0/OpenPI로 연구 공개성이 높고, Figure는 humanoid hardware와 회사 발표가 강하며, Generalist와 Skild는 현재 공개 기술 세부가 제한적이다. 따라서 같은 표 안에서도 evidence tier를 분리해야 한다.라는 구체 시나리오를 보면, 사람의 시연만으로는 충분하지 않다. [8]처럼 사람-로봇 전환을 쉽게 만드는 인터페이스가 있어도, 접촉 힘과 실패 이유가 빠지면 policy는 다음 release에서 같은 실수를 반복한다. 따라서 episode schema는 observation, action, contact state, QA outcome, operator note를 같은 key로 묶어야 한다.
증거 수준도 분리해야 한다. [9] 같은 논문은 재현 가능한 benchmark와 방법론을 제공하는 반면, 회사 발표는 실제 배포 방향을 알려주지만 데이터 권리와 운영 metric은 제한적으로 공개한다. 제조사는 둘을 같은 표에 넣되 같은 무게로 읽으면 안 된다. peer-reviewed 또는 arXiv 근거, 공식 기술 페이지, press/media claim, 미검증 watchlist를 나누어야 한다.
제어 관점에서는 learned policy가 모든 것을 결정하지 않는다. force limit, guarded motion, fixture state, collision zone, rollback condition이 policy 앞뒤에 있어야 한다. 이 경계가 없으면 large-data 전략은 더 많은 데이터를 모아도 현장에서 더 많은 안전 stop과 rework를 만들 수 있다.
운영 관점에서는 성공률보다 실패의 재현성이 중요하다. 실패가 replay set으로 들어가고, 다음 model update가 그 replay set을 통과하고, 배포 후 같은 failure code가 줄어드는지 확인되어야 flywheel이 닫힌다. 이 장의 질문은 그래서 'Figure의 humanoid-stack 전략을 어떻게 설명할까'가 아니라, 어떤 로그가 없으면 이 주장이 현장에서 무너지는가이다.
Generalist와 Skild의 불확실성
Generalist와 Skild의 불확실성의 핵심은 공정 변수를 학습 가능한 형태로 남기는 것이다. [10]는 대규모 데이터가 embodiment와 task family를 넓힐 수 있음을 보여주지만, 제조 셀은 그보다 좁고 엄격하다. 같은 물체를 집어도 fixture tolerance, 표면 오염, cycle time 압박, 검사기의 reject code가 달라지면 사실상 다른 데이터 분포가 된다.
여기서 PI는 pi0/OpenPI로 연구 공개성이 높고, Figure는 humanoid hardware와 회사 발표가 강하며, Generalist와 Skild는 현재 공개 기술 세부가 제한적이다. 따라서 같은 표 안에서도 evidence tier를 분리해야 한다.라는 구체 시나리오를 보면, 사람의 시연만으로는 충분하지 않다. [11]처럼 사람-로봇 전환을 쉽게 만드는 인터페이스가 있어도, 접촉 힘과 실패 이유가 빠지면 policy는 다음 release에서 같은 실수를 반복한다. 따라서 episode schema는 observation, action, contact state, QA outcome, operator note를 같은 key로 묶어야 한다.
증거 수준도 분리해야 한다. [12] 같은 논문은 재현 가능한 benchmark와 방법론을 제공하는 반면, 회사 발표는 실제 배포 방향을 알려주지만 데이터 권리와 운영 metric은 제한적으로 공개한다. 제조사는 둘을 같은 표에 넣되 같은 무게로 읽으면 안 된다. peer-reviewed 또는 arXiv 근거, 공식 기술 페이지, press/media claim, 미검증 watchlist를 나누어야 한다.
제어 관점에서는 learned policy가 모든 것을 결정하지 않는다. force limit, guarded motion, fixture state, collision zone, rollback condition이 policy 앞뒤에 있어야 한다. 이 경계가 없으면 large-data 전략은 더 많은 데이터를 모아도 현장에서 더 많은 안전 stop과 rework를 만들 수 있다.
운영 관점에서는 성공률보다 실패의 재현성이 중요하다. 실패가 replay set으로 들어가고, 다음 model update가 그 replay set을 통과하고, 배포 후 같은 failure code가 줄어드는지 확인되어야 flywheel이 닫힌다. 이 장의 질문은 그래서 'Generalist와 Skild의 불확실성을 어떻게 설명할까'가 아니라, 어떤 로그가 없으면 이 주장이 현장에서 무너지는가이다.
제조 관점의 evidence tier
제조 관점의 evidence tier의 핵심은 공정 변수를 학습 가능한 형태로 남기는 것이다. [13]는 대규모 데이터가 embodiment와 task family를 넓힐 수 있음을 보여주지만, 제조 셀은 그보다 좁고 엄격하다. 같은 물체를 집어도 fixture tolerance, 표면 오염, cycle time 압박, 검사기의 reject code가 달라지면 사실상 다른 데이터 분포가 된다.
여기서 PI는 pi0/OpenPI로 연구 공개성이 높고, Figure는 humanoid hardware와 회사 발표가 강하며, Generalist와 Skild는 현재 공개 기술 세부가 제한적이다. 따라서 같은 표 안에서도 evidence tier를 분리해야 한다.라는 구체 시나리오를 보면, 사람의 시연만으로는 충분하지 않다. [14]처럼 사람-로봇 전환을 쉽게 만드는 인터페이스가 있어도, 접촉 힘과 실패 이유가 빠지면 policy는 다음 release에서 같은 실수를 반복한다. 따라서 episode schema는 observation, action, contact state, QA outcome, operator note를 같은 key로 묶어야 한다.
증거 수준도 분리해야 한다. [15] 같은 논문은 재현 가능한 benchmark와 방법론을 제공하는 반면, 회사 발표는 실제 배포 방향을 알려주지만 데이터 권리와 운영 metric은 제한적으로 공개한다. 제조사는 둘을 같은 표에 넣되 같은 무게로 읽으면 안 된다. peer-reviewed 또는 arXiv 근거, 공식 기술 페이지, press/media claim, 미검증 watchlist를 나누어야 한다.
제어 관점에서는 learned policy가 모든 것을 결정하지 않는다. force limit, guarded motion, fixture state, collision zone, rollback condition이 policy 앞뒤에 있어야 한다. 이 경계가 없으면 large-data 전략은 더 많은 데이터를 모아도 현장에서 더 많은 안전 stop과 rework를 만들 수 있다.
운영 관점에서는 성공률보다 실패의 재현성이 중요하다. 실패가 replay set으로 들어가고, 다음 model update가 그 replay set을 통과하고, 배포 후 같은 failure code가 줄어드는지 확인되어야 flywheel이 닫힌다. 이 장의 질문은 그래서 '제조 관점의 evidence tier을 어떻게 설명할까'가 아니라, 어떤 로그가 없으면 이 주장이 현장에서 무너지는가이다.
제조 셀 적용 체크포인트
PoC를 시작할 때는 모델 후보보다 데이터 계약서를 먼저 쓴다. PI는 pi0/OpenPI로 연구 공개성이 높고, Figure는 humanoid hardware와 회사 발표가 강하며, Generalist와 Skild는 현재 공개 기술 세부가 제한적이다. 따라서 같은 표 안에서도 evidence tier를 분리해야 한다. 이 계약서에는 episode ID, 작업자/teleop ID, hand 또는 tool ID, contact channel, controller mode, 품질 판정, defect code, override 이유, rollback 조건이 들어간다. 이 항목을 vendor가 숨기거나 export하지 못하면 제조사는 model improvement의 원인을 설명할 수 없다.
두 번째 체크포인트는 evidence tier다. arXiv나 DOI가 있는 연구는 방법론 근거로 쓰고, 회사 공식 페이지는 제품 방향과 공개 claim으로 쓰며, press나 watchlist는 본문에서 단정하지 않는다. 특히 PI, Generalist, Skild, Figure, Covariant, Dexterity, Chef Robotics, Sunday, Config, CarbonSix 같은 회사는 서로 공개 수준이 다르다. 같은 'data-driven'이라는 표현 아래 묶되, 제조 readiness의 증거는 따로 평가해야 한다.
열린 문제와 실패 모드
첫째, 대규모 데이터가 있어도 접촉 상태가 빠지면 삽입, 닦기, deformable handling, tool use는 반복 실패한다. 둘째, 데이터 권리가 vendor에게만 있으면 제조사는 공정 개선의 원인을 소유하지 못한다. 셋째, worker video와 process IP는 학습 자산이면서 동시에 거버넌스 위험이다. 넷째, sim-to-real 데이터가 실제 QA label과 연결되지 않으면 simulation throughput은 공장 성능을 보장하지 않는다.
데이터 계약 보강
이 관점에서 중요한 것은 모델 이름이 아니라 관측 단위다. 공정은 사람이 보기에는 같은 작업처럼 보여도, 로봇에게는 표면 마찰, 시작 자세, 접촉 순서, 힘 제한, 검사 기준이 다른 여러 분포로 나타난다. 그래서 데이터 전략은 success clip을 모으는 캠페인이 아니라, 어떤 실패가 어떤 공정 변수와 연결되는지 추적하는 운영 체계가 된다.
제조 현장의 데이터는 실험실 벤치마크보다 느리고 지저분하지만 더 결정적인 신호를 갖고 있다. 불량, 재작업, 작업자 개입, 라인 정지, 안전 stop은 모델 학습에서 피하고 싶은 noise가 아니라 배포 가능한 policy를 만드는 label이다. 이 label이 episode와 분리되면 learning curve는 올라가도 공정 KPI는 움직이지 않는다.
따라서 large-data driven manipulation은 VLA 하나를 고르는 문제가 아니다. task schema, hand choice, controller boundary, replay set, QA trace, update governance를 함께 설계해야 한다. 이 설계가 없으면 foundation model은 데모를 만들 수 있어도 제조사가 원하는 반복 가능한 대체 노동이 되기 어렵다.
운영 루프 보강
이 관점에서 중요한 것은 모델 이름이 아니라 관측 단위다. 공정은 사람이 보기에는 같은 작업처럼 보여도, 로봇에게는 표면 마찰, 시작 자세, 접촉 순서, 힘 제한, 검사 기준이 다른 여러 분포로 나타난다. 그래서 데이터 전략은 success clip을 모으는 캠페인이 아니라, 어떤 실패가 어떤 공정 변수와 연결되는지 추적하는 운영 체계가 된다.
제조 현장의 데이터는 실험실 벤치마크보다 느리고 지저분하지만 더 결정적인 신호를 갖고 있다. 불량, 재작업, 작업자 개입, 라인 정지, 안전 stop은 모델 학습에서 피하고 싶은 noise가 아니라 배포 가능한 policy를 만드는 label이다. 이 label이 episode와 분리되면 learning curve는 올라가도 공정 KPI는 움직이지 않는다.
따라서 large-data driven manipulation은 VLA 하나를 고르는 문제가 아니다. task schema, hand choice, controller boundary, replay set, QA trace, update governance를 함께 설계해야 한다. 이 설계가 없으면 foundation model은 데모를 만들 수 있어도 제조사가 원하는 반복 가능한 대체 노동이 되기 어렵다.
배포 거버넌스 보강
이 관점에서 중요한 것은 모델 이름이 아니라 관측 단위다. 공정은 사람이 보기에는 같은 작업처럼 보여도, 로봇에게는 표면 마찰, 시작 자세, 접촉 순서, 힘 제한, 검사 기준이 다른 여러 분포로 나타난다. 그래서 데이터 전략은 success clip을 모으는 캠페인이 아니라, 어떤 실패가 어떤 공정 변수와 연결되는지 추적하는 운영 체계가 된다.
제조 현장의 데이터는 실험실 벤치마크보다 느리고 지저분하지만 더 결정적인 신호를 갖고 있다. 불량, 재작업, 작업자 개입, 라인 정지, 안전 stop은 모델 학습에서 피하고 싶은 noise가 아니라 배포 가능한 policy를 만드는 label이다. 이 label이 episode와 분리되면 learning curve는 올라가도 공정 KPI는 움직이지 않는다.
따라서 large-data driven manipulation은 VLA 하나를 고르는 문제가 아니다. task schema, hand choice, controller boundary, replay set, QA trace, update governance를 함께 설계해야 한다. 이 설계가 없으면 foundation model은 데모를 만들 수 있어도 제조사가 원하는 반복 가능한 대체 노동이 되기 어렵다.
다음에 배울 것
다음 장은 같은 원칙을 다른 손과 end-effector에 적용한다. 어떤 작업은 2지와 흡착으로 충분하고, 어떤 작업은 5지 손과 tactile/force-rich data 없이는 데이터가 닫히지 않는다.
참고문헌
- Black, Kevin (2024). pi0: A Vision-Language-Action Flow Model for General Robot Control. arXiv.
- Physical Intelligence (2024). pi0: A Generalist Robot Policy. Company research post.
- Physical Intelligence (2025). OpenPI: Open Source Robot Policy Stack. GitHub.
- Kim, Moo Jin (2024). OpenVLA: An Open-Source Vision-Language-Action Model. arXiv.
- Octo Model Team (2024). Octo: An Open-Source Generalist Robot Policy. arXiv.
- O'Neill, Abby (2023). Open X-Embodiment: Robotic Learning Datasets and RT-X Models. arXiv.
- Pertsch, Karl (2025). FAST: Efficient Action Tokenization for Vision-Language-Action Models. arXiv.
- Shukla, Shivin (2025). SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics. arXiv.
- DeepMind Robotics Team (2025). Gemini Robotics: Bringing AI into the Physical World. arXiv.
- Bjorck, Johan (2025). GR00T N1: An Open Foundation Model for Generalist Humanoid Robots. arXiv.
- NVIDIA (2025). Isaac GR00T N1 Open Foundation Model for Humanoid Robots. NVIDIA Developer.
- Figure AI (2025). Helix: A Vision-Language-Action Model for Generalist Humanoid Control. Company announcement.
- Figure AI (2026). Figure 03 + Helix 02: General-Purpose Humanoid System. Company product page.
- Generalist AI (2025). GEN-0 Robot Foundation Model. Company page.
- Skild AI (2024). General-Purpose Robot Brain. Company page.
- Zheng, Renhao (2026). EgoScale: Scaling Dexterous Manipulation with Diverse Egocentric Human Data. NVIDIA Research.
- Yu, Wenhao (2025). ForceVLA: Enhancing VLA Models with a Force-aware MoE for Contact-rich Manipulation. arXiv.
- Huang, Yuhang (2025). Tactile-VLA: Unlocking Vision-Language-Action Model's Physical Knowledge for Tactile Generalization. arXiv.
- Khazatsky, Alexander (2024). DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset. arXiv.
- AgiBot World Team (2025). AgiBot World Colosseo: A Large-Scale Manipulation Platform. arXiv.
- Zhao, Tony Z. (2023). Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware. arXiv.
- Chi, Cheng (2023). Diffusion Policy: Visuomotor Policy Learning via Action Diffusion. arXiv.
- Ha, Huy (2024). Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots. arXiv.
- Toyota Research Institute (2024). Large Behavior Models for Robot Manipulation. Company technical post.