Chapter 2: Choosing the Hand: Two Fingers, Suction, Custom Hands, and Five Fingers
Overview
Choosing the end-effector is a decision about the coordinate system of the data distribution, not merely a hardware purchase. This chapter rewrites the problem as a factory-cell data contract. The promise of large robot datasets in [1] and [2] matters, but in manufacturing an episode becomes valuable only when it is attached to inspection and process outcomes.
Suction gives high pick throughput but poor contact observability; two-finger grippers record force, torque, and regrasp more cleanly; five-finger hands unlock tool use and deformables while increasing data and maintenance costs. The data is therefore not just a camera stream. It includes hand choice, force-torque, tactile patches, controller mode, operator intervention, and inspection result. [3] and [4] show why human-to-robot transfer loses critical signals unless the capture interface is designed around embodiment and contact.
After reading this chapter... - Explain factory manipulation as a data contract rather than a model score. - Separate two-finger, suction, custom, and five-finger choices by collection cost and failure observability. - Read papers, company releases, and deployment claims through evidence tiers. - Design the replay set and QA trace required for a first manufacturing PoC.
Core Map
| Decision axis | Data that must remain observable | Factory-cell decision |
|---|---|---|
| Task distribution | SKU, lot, fixture, contact event, inspection result | Decide whether one policy family is enough or the cell needs task-specific policies [1] |
| Hardware | Gripper, hand, tactile/force channel, calibration state | Compare suction, two fingers, custom tools, and five-finger hands by data cost [2] |
| Operations log | Override, stop, rework, scrap, cycle time | Set retraining triggers and rollback criteria [3] |
Visual Argument

Figure 2.1. End-effector taxonomy as data strategy. Source: reused local survey asset or author-created illustration.

Figure 2.2. GelSight Wedge shows tactile geometry for robot fingers. Source: reused local survey asset or author-created illustration.
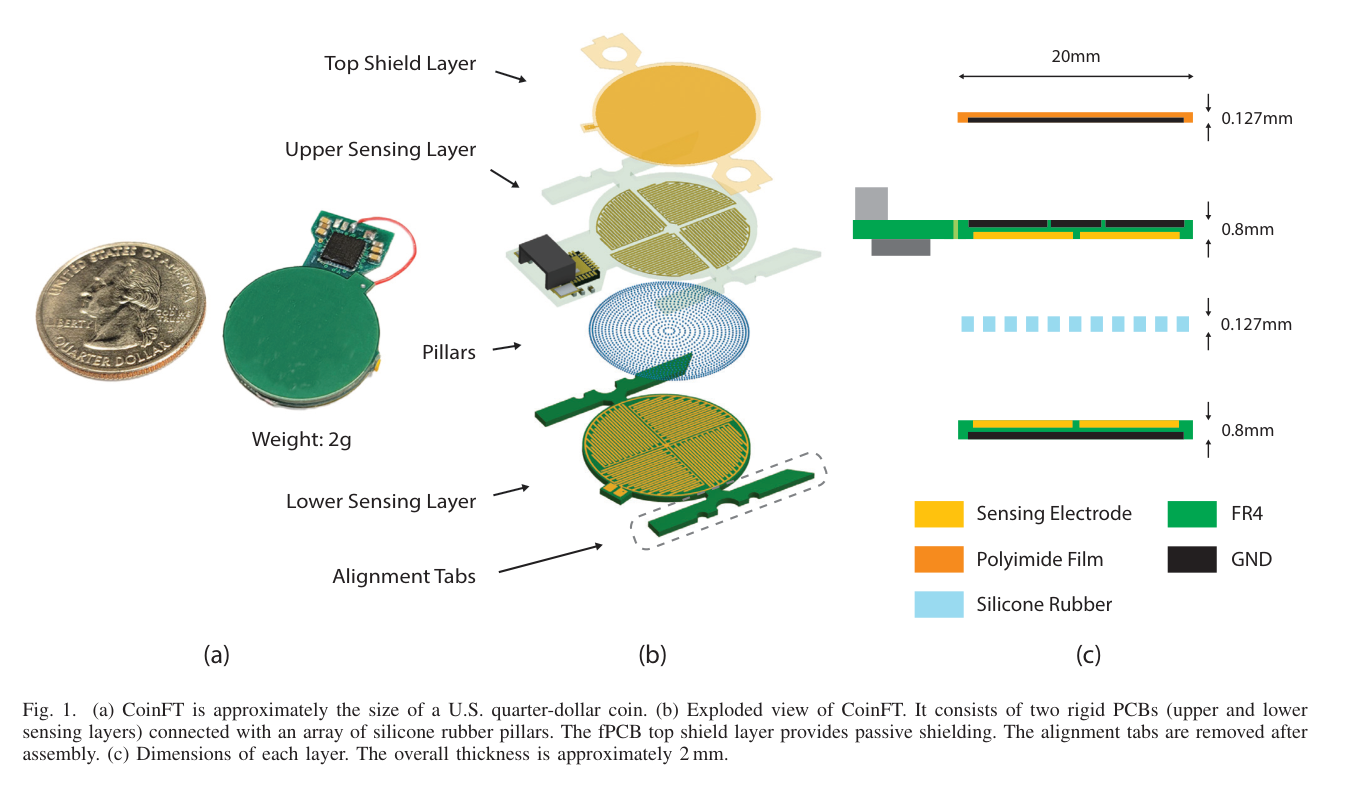
Figure 2.3. Compact force-torque sensing changes the hand data contract. Source: reused local survey asset or author-created illustration.
The Hand Is the First Task Classifier
The practical meaning of the hand is the first task classifier is that process variables must be left in a learnable form. [1] shows how scale can broaden embodiment and task families, yet a factory cell is narrower and stricter. A pick that looks identical to a person can become a different distribution when fixture tolerance, surface contamination, cycle pressure, or reject code changes.
In the concrete scenario, Suction gives high pick throughput but poor contact observability; two-finger grippers record force, torque, and regrasp more cleanly; five-finger hands unlock tool use and deformables while increasing data and maintenance costs. Human demonstrations alone are not enough. Even when an interface such as [2] makes collection easier, a policy will repeat the same release failure if contact force and failure cause are absent. The episode schema must bind observation, action, contact state, QA outcome, and operator note under one key.
The evidence tier matters. A source such as [3] gives a method and benchmark that can be inspected. A company source can reveal deployment direction, but usually exposes less about data rights, recovery handling, and operating metrics. Manufacturers should place both in the same comparison table but never read them with the same confidence.
From a control perspective, the learned policy should not be the whole system. Force limits, guarded motion, fixture state, collision zones, and rollback conditions have to sit around the model. Without that boundary, collecting more data can create more safety stops and more rework instead of a more deployable robot.
From an operating perspective, the reproducibility of failure matters more than a headline success rate. A failure has to enter a replay set, the next update has to pass that replay set, and the deployed cell has to show a lower rate for the same failure code. The question is not only how to describe the hand is the first task classifier, but which missing log would make the claim collapse on a line.
Why Two Fingers and Suction Still Win Often
The practical meaning of why two fingers and suction still win often is that process variables must be left in a learnable form. [4] shows how scale can broaden embodiment and task families, yet a factory cell is narrower and stricter. A pick that looks identical to a person can become a different distribution when fixture tolerance, surface contamination, cycle pressure, or reject code changes.
In the concrete scenario, Suction gives high pick throughput but poor contact observability; two-finger grippers record force, torque, and regrasp more cleanly; five-finger hands unlock tool use and deformables while increasing data and maintenance costs. Human demonstrations alone are not enough. Even when an interface such as [5] makes collection easier, a policy will repeat the same release failure if contact force and failure cause are absent. The episode schema must bind observation, action, contact state, QA outcome, and operator note under one key.
The evidence tier matters. A source such as [6] gives a method and benchmark that can be inspected. A company source can reveal deployment direction, but usually exposes less about data rights, recovery handling, and operating metrics. Manufacturers should place both in the same comparison table but never read them with the same confidence.
From a control perspective, the learned policy should not be the whole system. Force limits, guarded motion, fixture state, collision zones, and rollback conditions have to sit around the model. Without that boundary, collecting more data can create more safety stops and more rework instead of a more deployable robot.
From an operating perspective, the reproducibility of failure matters more than a headline success rate. A failure has to enter a replay set, the next update has to pass that replay set, and the deployed cell has to show a lower rate for the same failure code. The question is not only how to describe why two fingers and suction still win often, but which missing log would make the claim collapse on a line.
When Five Fingers Become Justified
The practical meaning of when five fingers become justified is that process variables must be left in a learnable form. [7] shows how scale can broaden embodiment and task families, yet a factory cell is narrower and stricter. A pick that looks identical to a person can become a different distribution when fixture tolerance, surface contamination, cycle pressure, or reject code changes.
In the concrete scenario, Suction gives high pick throughput but poor contact observability; two-finger grippers record force, torque, and regrasp more cleanly; five-finger hands unlock tool use and deformables while increasing data and maintenance costs. Human demonstrations alone are not enough. Even when an interface such as [8] makes collection easier, a policy will repeat the same release failure if contact force and failure cause are absent. The episode schema must bind observation, action, contact state, QA outcome, and operator note under one key.
The evidence tier matters. A source such as [9] gives a method and benchmark that can be inspected. A company source can reveal deployment direction, but usually exposes less about data rights, recovery handling, and operating metrics. Manufacturers should place both in the same comparison table but never read them with the same confidence.
From a control perspective, the learned policy should not be the whole system. Force limits, guarded motion, fixture state, collision zones, and rollback conditions have to sit around the model. Without that boundary, collecting more data can create more safety stops and more rework instead of a more deployable robot.
From an operating perspective, the reproducibility of failure matters more than a headline success rate. A failure has to enter a replay set, the next update has to pass that replay set, and the deployed cell has to show a lower rate for the same failure code. The question is not only how to describe when five fingers become justified, but which missing log would make the claim collapse on a line.
Touch and Force Are Part of the Hand
The practical meaning of touch and force are part of the hand is that process variables must be left in a learnable form. [10] shows how scale can broaden embodiment and task families, yet a factory cell is narrower and stricter. A pick that looks identical to a person can become a different distribution when fixture tolerance, surface contamination, cycle pressure, or reject code changes.
In the concrete scenario, Suction gives high pick throughput but poor contact observability; two-finger grippers record force, torque, and regrasp more cleanly; five-finger hands unlock tool use and deformables while increasing data and maintenance costs. Human demonstrations alone are not enough. Even when an interface such as [11] makes collection easier, a policy will repeat the same release failure if contact force and failure cause are absent. The episode schema must bind observation, action, contact state, QA outcome, and operator note under one key.
The evidence tier matters. A source such as [12] gives a method and benchmark that can be inspected. A company source can reveal deployment direction, but usually exposes less about data rights, recovery handling, and operating metrics. Manufacturers should place both in the same comparison table but never read them with the same confidence.
From a control perspective, the learned policy should not be the whole system. Force limits, guarded motion, fixture state, collision zones, and rollback conditions have to sit around the model. Without that boundary, collecting more data can create more safety stops and more rework instead of a more deployable robot.
From an operating perspective, the reproducibility of failure matters more than a headline success rate. A failure has to enter a replay set, the next update has to pass that replay set, and the deployed cell has to show a lower rate for the same failure code. The question is not only how to describe touch and force are part of the hand, but which missing log would make the claim collapse on a line.
A Hand Taxonomy by Data Cost
The practical meaning of a hand taxonomy by data cost is that process variables must be left in a learnable form. [13] shows how scale can broaden embodiment and task families, yet a factory cell is narrower and stricter. A pick that looks identical to a person can become a different distribution when fixture tolerance, surface contamination, cycle pressure, or reject code changes.
In the concrete scenario, Suction gives high pick throughput but poor contact observability; two-finger grippers record force, torque, and regrasp more cleanly; five-finger hands unlock tool use and deformables while increasing data and maintenance costs. Human demonstrations alone are not enough. Even when an interface such as [14] makes collection easier, a policy will repeat the same release failure if contact force and failure cause are absent. The episode schema must bind observation, action, contact state, QA outcome, and operator note under one key.
The evidence tier matters. A source such as [15] gives a method and benchmark that can be inspected. A company source can reveal deployment direction, but usually exposes less about data rights, recovery handling, and operating metrics. Manufacturers should place both in the same comparison table but never read them with the same confidence.
From a control perspective, the learned policy should not be the whole system. Force limits, guarded motion, fixture state, collision zones, and rollback conditions have to sit around the model. Without that boundary, collecting more data can create more safety stops and more rework instead of a more deployable robot.
From an operating perspective, the reproducibility of failure matters more than a headline success rate. A failure has to enter a replay set, the next update has to pass that replay set, and the deployed cell has to show a lower rate for the same failure code. The question is not only how to describe a hand taxonomy by data cost, but which missing log would make the claim collapse on a line.
Manufacturing Cell Checkpoint
Start a PoC by writing the data contract before selecting the model. Suction gives high pick throughput but poor contact observability; two-finger grippers record force, torque, and regrasp more cleanly; five-finger hands unlock tool use and deformables while increasing data and maintenance costs. The contract should include episode ID, operator or teleop ID, hand or tool ID, contact channel, controller mode, quality decision, defect code, override reason, and rollback condition. If a vendor hides or cannot export these fields, the manufacturer cannot explain why model improvement happens.
The second checkpoint is evidence tiering. Papers with arXiv or DOI links support method claims; official company pages support product-direction claims; press and watchlist items should not become load-bearing claims. PI, Generalist, Skild, Figure, Covariant, Dexterity, Chef Robotics, Sunday, Config, and CarbonSix all fit under data-driven manipulation, but they expose very different evidence about manufacturing readiness.
Open Questions and Failure Modes
First, large data without contact state leaves insertion, wiping, deformable handling, and tool use under-observed. Second, when data rights stay entirely with the vendor, the manufacturer does not own the cause of process improvement. Third, worker video and process IP are learning assets and governance risks at the same time. Fourth, sim-to-real data does not guarantee factory performance unless it is tied to real QA labels.
Data Contract Addendum
The important unit is not the model name but the observable attempt. To a human, two factory cycles can look like the same task; to a robot, they may differ in surface friction, initial pose, contact order, force limit, and inspection rule. Data strategy is therefore an operating system for connecting failures to process variables, not a campaign for collecting success clips.
Factory data is slower and messier than benchmark data, but it carries more decisive labels. Defect codes, rework, operator intervention, line stops, and safety stops are not noise to be hidden from learning. They are the labels that decide whether a policy can be deployed. If those labels are detached from episodes, model curves can improve while process KPIs stay flat.
Large-data driven manipulation is therefore not a choice of one VLA. It is a joint design of task schema, hand choice, controller boundary, replay set, QA trace, and update governance. Without that design, a foundation model may produce impressive demonstrations without becoming repeatable replacement labor in manufacturing.
Operating Loop Addendum
The important unit is not the model name but the observable attempt. To a human, two factory cycles can look like the same task; to a robot, they may differ in surface friction, initial pose, contact order, force limit, and inspection rule. Data strategy is therefore an operating system for connecting failures to process variables, not a campaign for collecting success clips.
Factory data is slower and messier than benchmark data, but it carries more decisive labels. Defect codes, rework, operator intervention, line stops, and safety stops are not noise to be hidden from learning. They are the labels that decide whether a policy can be deployed. If those labels are detached from episodes, model curves can improve while process KPIs stay flat.
Large-data driven manipulation is therefore not a choice of one VLA. It is a joint design of task schema, hand choice, controller boundary, replay set, QA trace, and update governance. Without that design, a foundation model may produce impressive demonstrations without becoming repeatable replacement labor in manufacturing.
Deployment Governance Addendum
The important unit is not the model name but the observable attempt. To a human, two factory cycles can look like the same task; to a robot, they may differ in surface friction, initial pose, contact order, force limit, and inspection rule. Data strategy is therefore an operating system for connecting failures to process variables, not a campaign for collecting success clips.
Factory data is slower and messier than benchmark data, but it carries more decisive labels. Defect codes, rework, operator intervention, line stops, and safety stops are not noise to be hidden from learning. They are the labels that decide whether a policy can be deployed. If those labels are detached from episodes, model curves can improve while process KPIs stay flat.
Large-data driven manipulation is therefore not a choice of one VLA. It is a joint design of task schema, hand choice, controller boundary, replay set, QA trace, and update governance. Without that design, a foundation model may produce impressive demonstrations without becoming repeatable replacement labor in manufacturing.
What to Learn Next
The next chapter applies the same principle to hands and end-effectors. Some cells are best served by suction or two fingers; others cannot close the data loop without five-finger hands and tactile or force-rich data.
References
- Shaw, Kenneth (2023). LEAP Hand: Low-Cost, Efficient, and Anthropomorphic Hand for Robot Learning. arXiv.
- Lambeta, Mike (2020). DIGIT: A Novel Design for a Low-Cost Compact High-Resolution Tactile Sensor with Application to In-Hand Manipulation. arXiv.
- Lambeta, Mike (2024). Digitizing Touch with an Artificial Multimodal Fingertip. arXiv.
- Bhirangi, Raunaq (2021). ReSkin: Versatile, Replaceable, Lasting Tactile Skins. arXiv.
- Bhirangi, Raunaq (2024). AnySkin: Plug-and-play Skin Sensing for Robotic Touch. arXiv.
- Choi, Hojung (2025). CoinFT: A Coin-Sized, Capacitive 6-Axis Force Torque Sensor for Robotic Applications. arXiv.
- Feng, Ruoxuan (2025). AnyTouch: Learning Unified Static-Dynamic Representation across Multiple Visuo-Tactile Sensors. arXiv.
- Xu, Mengda (2025). DexUMI: Using Human Hand as the Universal Manipulation Interface for Dexterous Manipulation. arXiv.
- Fang, Hao-Shu (2025). DEXOP: Passive Exoskeleton for Direct-contact Dexterous Demonstration. arXiv.
- Si, Zilin (2025). ExoStart: From 10 Exoskeleton Demos to Dexterous Robot Manipulation. arXiv.
- Choi, Hojung (2026). In-the-Wild Compliant Manipulation with UMI-FT. arXiv.
- Ha, Huy (2024). Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots. arXiv.
- Yu, Wenhao (2025). ForceVLA: Enhancing VLA Models with a Force-aware MoE for Contact-rich Manipulation. arXiv.
- Huang, Yuhang (2025). Tactile-VLA: Unlocking Vision-Language-Action Model's Physical Knowledge for Tactile Generalization. arXiv.
- Hao, Yaru (2025). Tactile-Language-Action Model for Contact-Rich Manipulation. arXiv.
- Figure AI (2026). Figure 03 + Helix 02: General-Purpose Humanoid System. Company product page.
- Physical Intelligence (2024). pi0: A Generalist Robot Policy. Company research post.
- Zhao, Tony Z. (2023). Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware. arXiv.
- Chi, Cheng (2023). Diffusion Policy: Visuomotor Policy Learning via Action Diffusion. arXiv.
- Mandlekar, Ajay (2021). What Matters in Learning from Offline Human Demonstrations for Robot Manipulation. arXiv.
- O'Neill, Abby (2023). Open X-Embodiment: Robotic Learning Datasets and RT-X Models. arXiv.
- Khazatsky, Alexander (2024). DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset. arXiv.
- Toyota Research Institute (2024). Large Behavior Models for Robot Manipulation. Company technical post.
- AgiBot World Team (2025). AgiBot World Colosseo: A Large-Scale Manipulation Platform. arXiv.